The work does not end when something goes live
After enough deliveries, it becomes obvious that the real work begins after launch. A site, tool, or internal system still has to stay fast, available, secure, and predictable once people start depending on it.
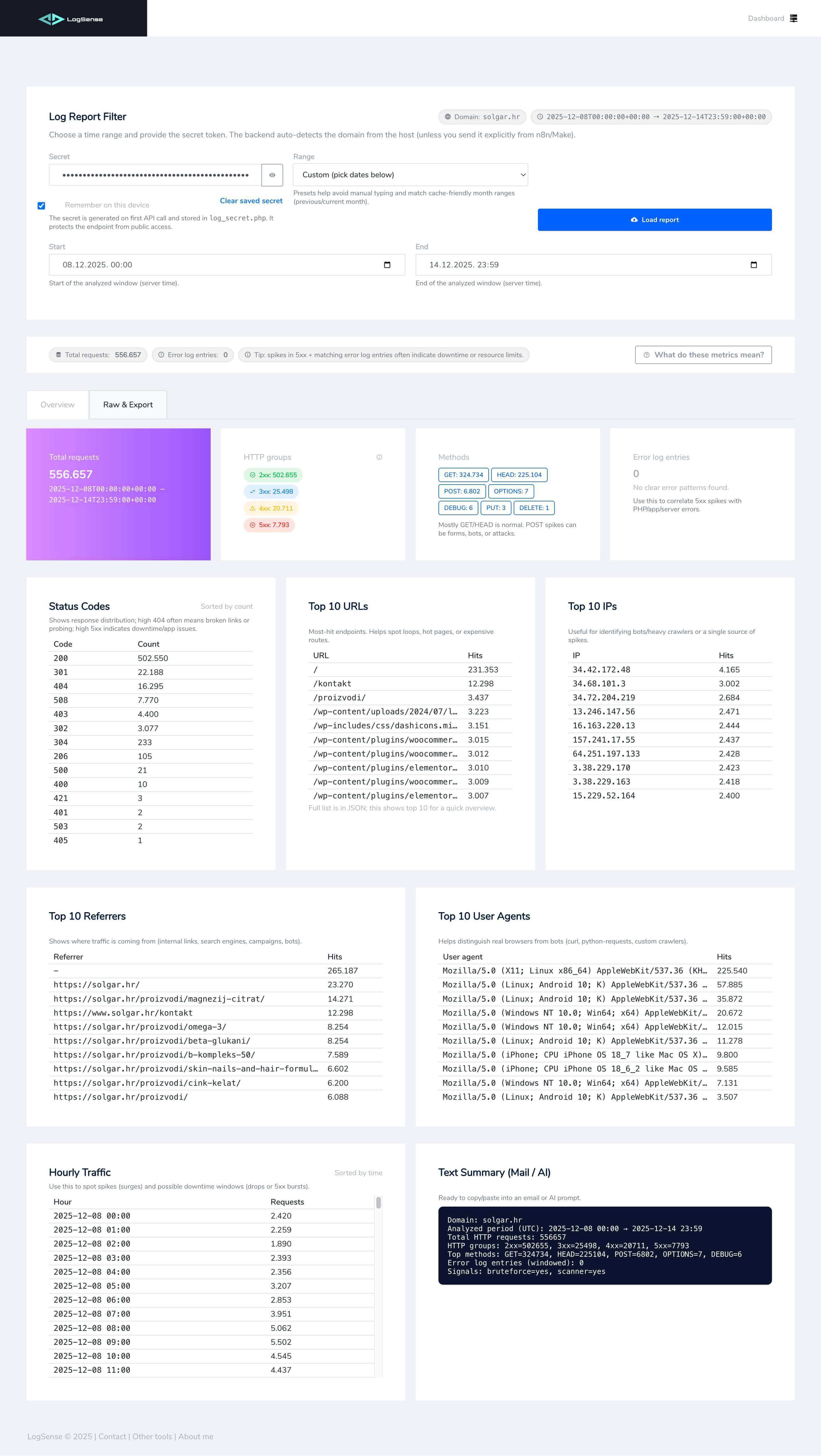
That is when a digital product starts to look a lot like infrastructure: performance, monitoring, logs, backups, security, incident handling, and maintenance cost all become part of the same operational picture.
Building something is not enough. It also needs an environment in which it can run reliably.
Monitoring changes the conversation
Once a system has even basic monitoring, the conversation moves from opinion to data. Response time, error rate, alerts, and trends make it easier to diagnose a problem without guessing.
- Is the slowdown in the frontend, backend, or an external integration?
- When did the issue start and what changed around that time?
- Is this an isolated spike or a repeating pattern?
- What is the actual operational impact?
Smaller systems still need signals
Smaller teams rarely need heavy enterprise platforms. What they do need are clear signals: availability, simple log analysis, alerts, status visibility, and an agreed response when something breaks.
Total cost is more than the starting price
Tooling and infrastructure choices should not be judged only by upfront cost. The real cost also includes maintenance time, outage risk, security exposure, diagnostic effort, and how painful future change will be.
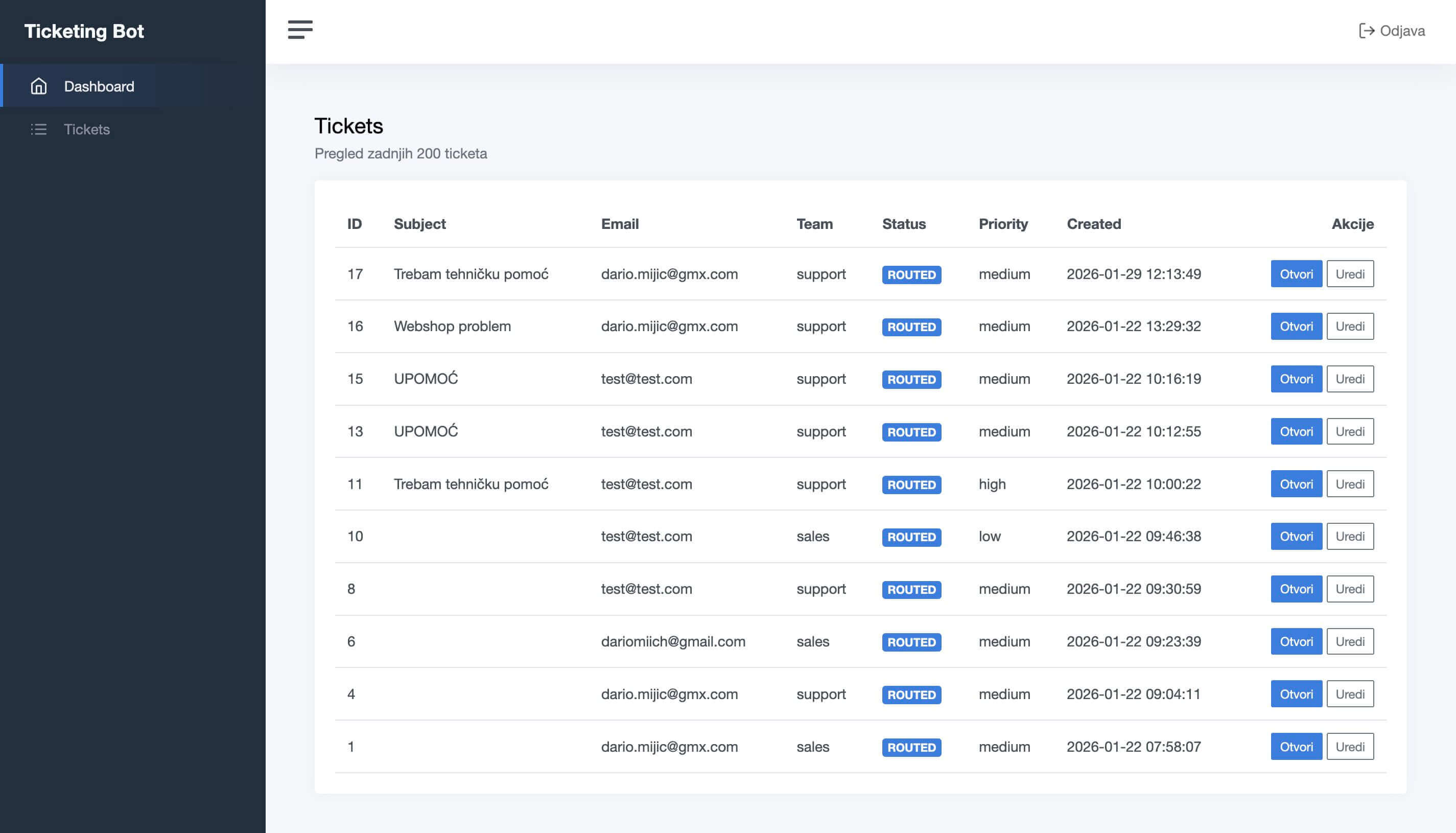
For Tokmatik, that means a cleaner operating model
Tokmatik does not treat a system as automation for one isolated step. A useful operational layer needs clean intake, clear rules, visible status, an exception path, and a way to maintain it later. What cannot be seen is hard to manage. What is not managed quickly becomes risk.