Problem
Organizacije često imaju puno korisne dokumentacije, ali ona nije laka za svakodnevnu upotrebu. Upute su u PDF-ovima, pravilnici u DOCX datotekama, procedure u internim mapama, a zaposlenici i dalje pitaju gdje se što nalazi.
Klasičan chatbot nije dovoljno dobar za taj problem. Ako nema pristup izvorima, lako izmišlja. Ako se u njega ubaci veliki PDF bez pripreme, retrieval često vraća preširoke dijelove i model pokušava odgovoriti iz nepotpunog konteksta.
Što je izgrađeno
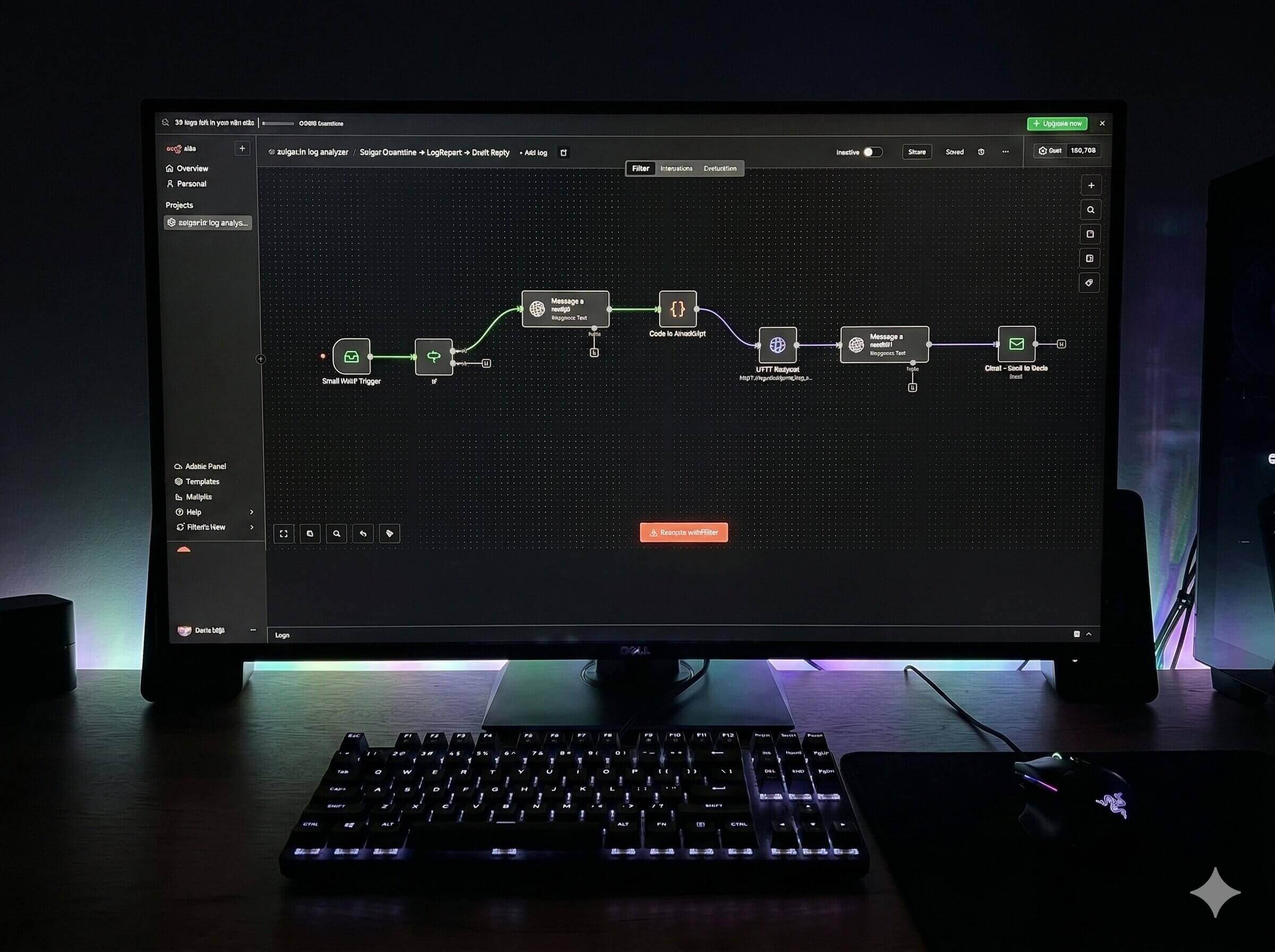
Izgrađena su dva povezana sloja. RAGnar je self-hosted lokalna RAG platforma za izradu asistenata nad privatnom dokumentacijom. RAGnar Knowledge Processor je pripremni Python pipeline koji PDF/DOCX dokumente čisti, dijeli po temama i sprema kao manje Markdown knowledge datoteke.
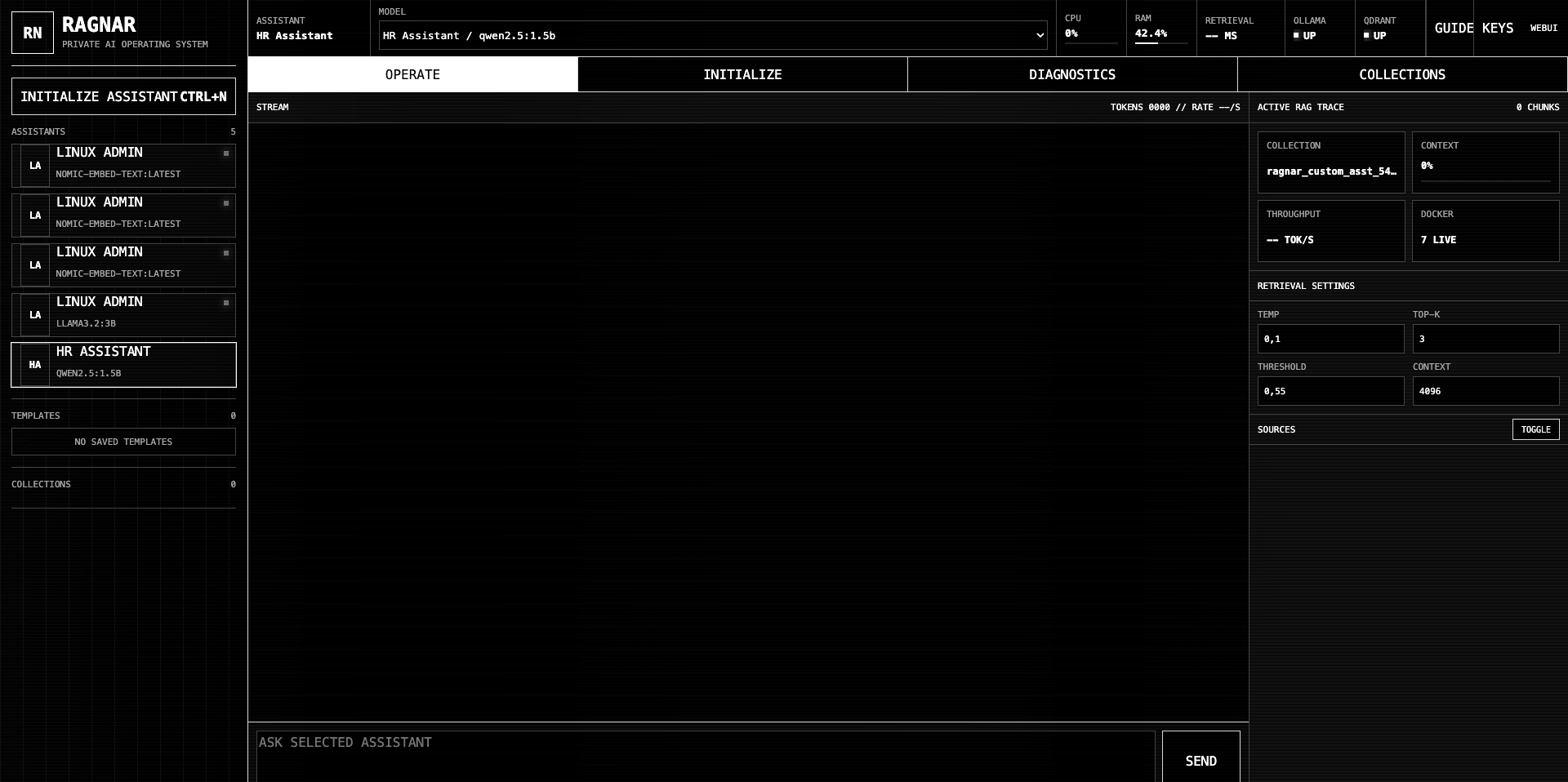
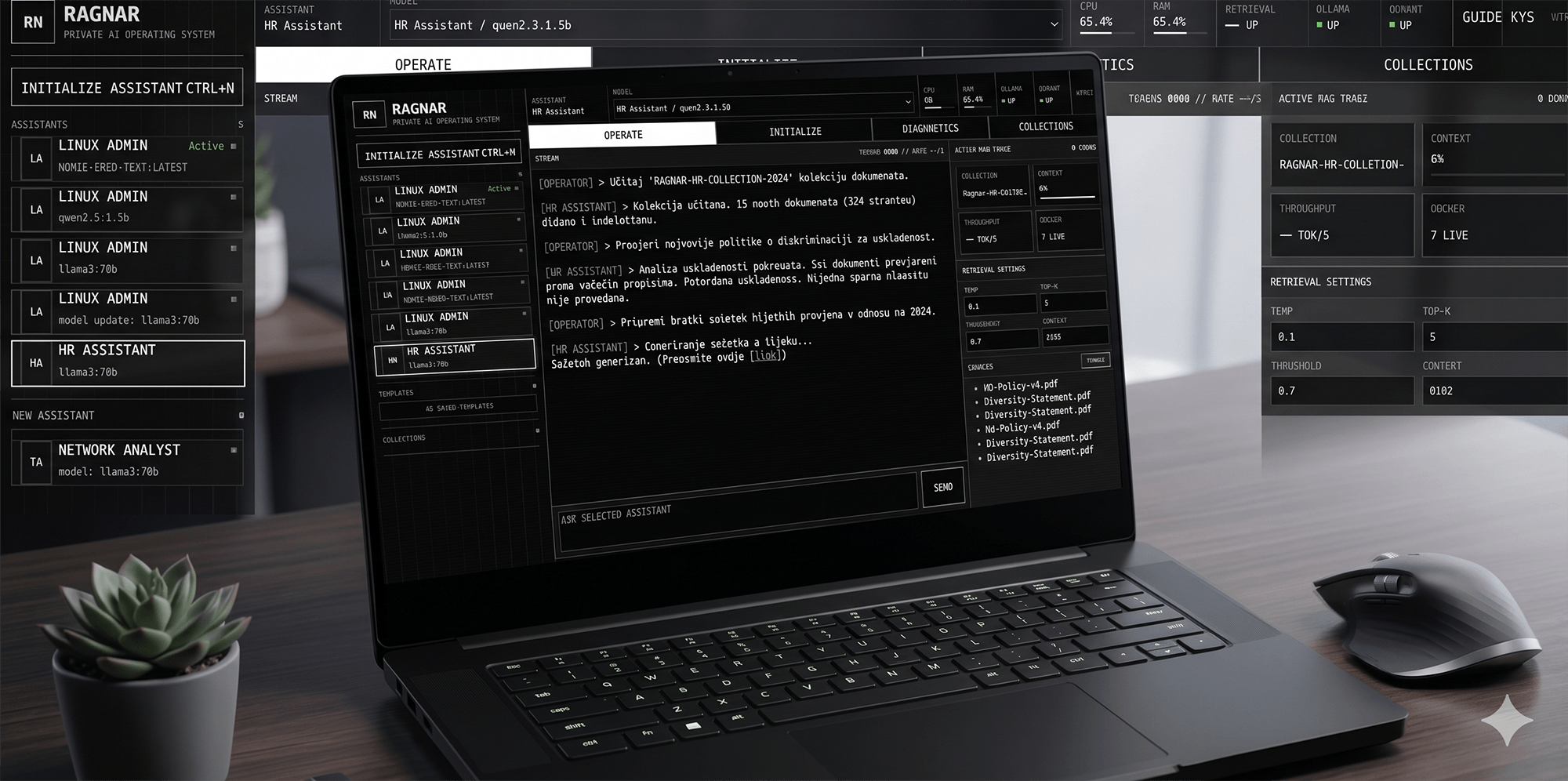
RAGnar omogućuje odabir modela, konfiguraciju retrievala, rad s lokalnim embeddingsima, Qdrant vector bazom i prikaz izvora. Knowledge Processor priprema ulaz tako da asistent ne mora raditi nad velikim, šumnim dokumentima.
Kako sustav radi
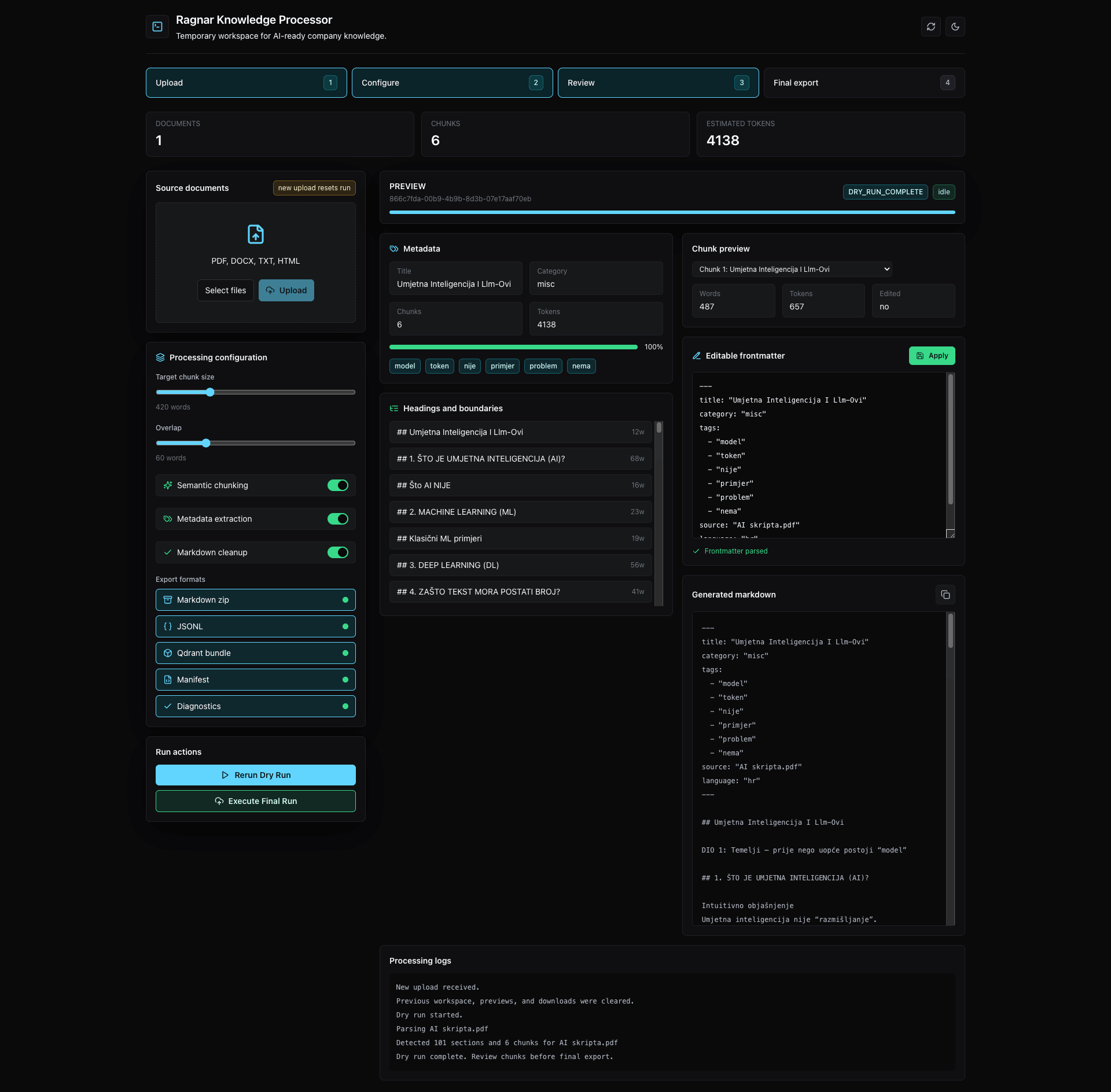
- PDF/DOCX dokument ulazi u Knowledge Processor.
- Pipeline izvlači tekst, normalizira ga i prepoznaje naslove ili tematske sekcije.
- Sadržaj se sprema u manje Markdown datoteke s naslovima, kategorijama, tagovima i source referencama.
- RAGnar ingestira te datoteke, generira embeddinge i sprema ih u Qdrant.
- Korisnik kreira asistenta, podešava chunk size, top-k, similarity threshold i temperaturu.
- Odgovor prikazuje dokumente, chunkove i source snippetove kako bi korisnik mogao provjeriti kontekst.
Arhitektura
Sustav je složen kao Docker Compose okruženje. Open WebUI služi kao chat i korisničko sučelje, Ollama pokreće lokalne modele, Qdrant čuva vector store, FastAPI upravlja RAGnar endpointima i konfiguracijom, a NGINX rješava routing između Open WebUI sučelja i RAGnar API-ja.
Poseban naglasak stavljen je na transparentnost: asistent ne bi trebao samo vratiti odgovor, nego pokazati koji dokument i koji dio teksta je korišten.
Operativna vrijednost
RAGnar je koristan kao temelj za više internih asistenata: HR procedure, IT dokumentaciju, Linux upute, networking skripte, sigurnosne politike ili onboarding materijale. Umjesto jednog općeg asistenta, svaki može imati svoju dokumentaciju i svoje retrieval postavke.
Knowledge Processor rješava problem koji se često preskoči u AI projektima: pripremu znanja prije samog chata. Manji i čišći Markdown izvori daju stabilniji retrieval, manje halucinacija i jasnije citiranje.
Što je naučeno
Najveća lekcija nije bila da treba veći model. Najveća lekcija je da treba bolji ulaz. Lokalni modeli mogu biti korisni ako je dokumentacija dobro pripremljena, chunkovi smisleni, a prompt dovoljno restriktivan.
Projekt je dobar primjer praktičnog AI engineeringa: infrastruktura, dokumentacijski pipeline, vector search, prompt pravila, source citations i stalno testiranje odgovora rade zajedno. Nijedan dio sam po sebi nije dovoljan.