Upload PDF-a nije isto što i knowledge system
U prvim RAG eksperimentima najlakše je napraviti ono što zvuči najbrže: uzeti veliki PDF, uploadati ga u sustav i očekivati da će AI odmah davati precizne odgovore. U praksi se vrlo brzo vidi da to nije dovoljno.
PDF može imati loš layout, preduge blokove teksta, pomiješane naslove, tablice, zaglavlja, fusnote i sadržaj koji je čovjeku čitljiv, ali modelu i vector bazi nije dovoljno čist. Tada retrieval vraća preširoke ili pogrešne dijelove dokumenta, a mali lokalni model pokušava sastaviti odgovor iz šuma.
RAGnar kao privatni AI sloj
RAGnar je self-hosted lokalna RAG platforma za izradu specijaliziranih asistenata nad privatnom dokumentacijom. Sustav koristi Docker, FastAPI, Open WebUI, Ollama, Qdrant i NGINX kako bi omogućio lokalni rad s dokumentima, embeddingsima, izvorima i konfiguracijom retrievala.
Poanta nije da model “zna sve”. Poanta je da sustav pronađe relevantne dijelove interne dokumentacije, proslijedi ih modelu i prikaže izvor iz kojeg je odgovor nastao.
Knowledge Processor kao pripremni sloj
RAGnar Knowledge Processor nastao je iz vrlo praktičnog problema: dokumenti koji su dobri za čitanje nisu nužno dobri za retrieval.
Ideja procesora je jednostavna: uzeti PDF ili DOCX dokument, izvući tekst, očistiti ga, prepoznati sekcije i pretvoriti veliki dokument u manje tematske Markdown datoteke. Umjesto jednog velikog izvora, dobiješ skup kraćih, jasnijih i lakše pretraživih knowledge jedinica.
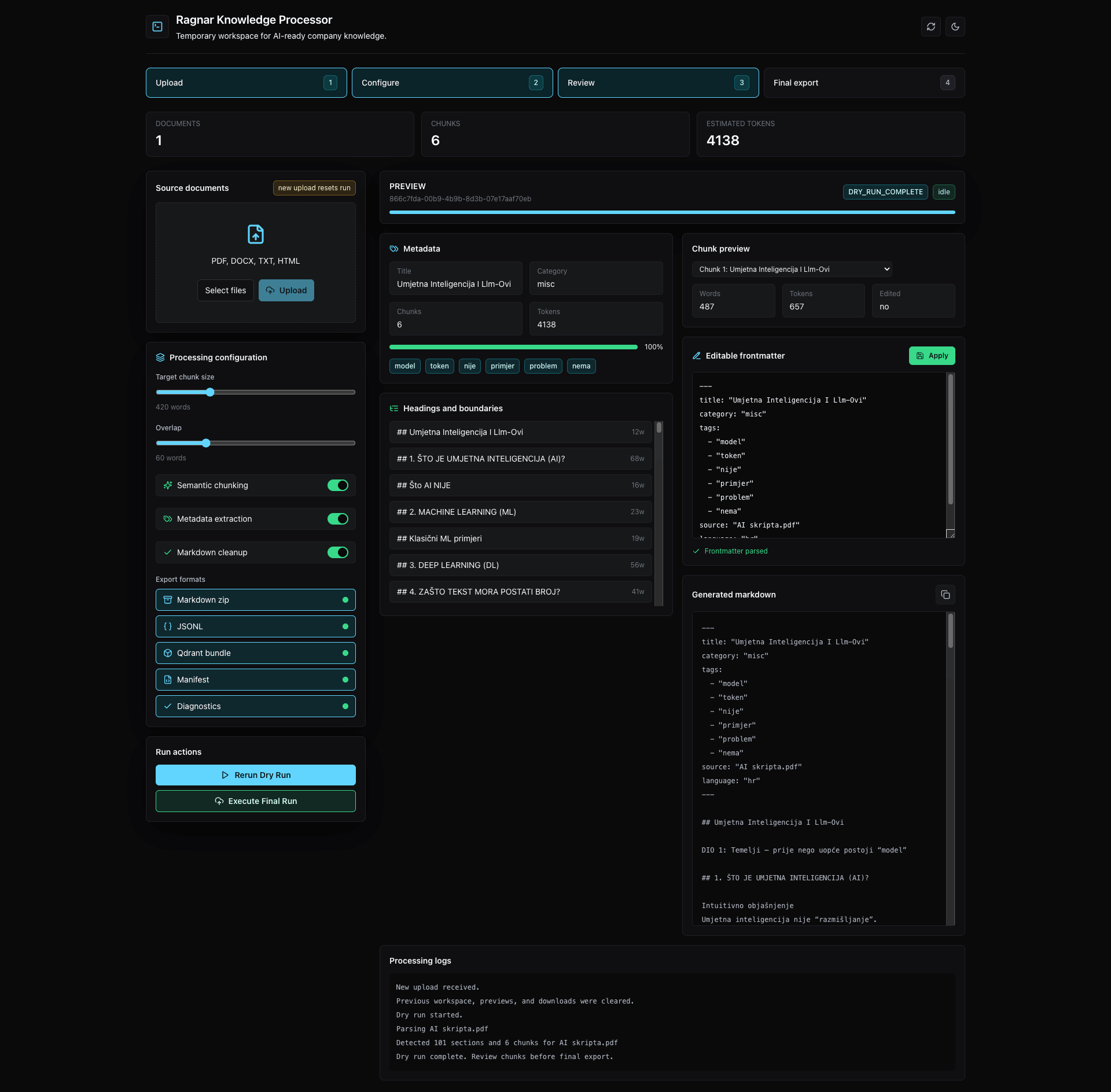
Što se time dobiva?
Kad su dokumenti razbijeni u manje i smislenije cjeline, retrieval postaje precizniji. Model dobiva manje šuma, odgovori su kraći i vezaniji uz izvor, a korisnik lakše vidi zašto je sustav nešto odgovorio.
To je posebno važno kod internih asistenata za HR, IT, sigurnosne procedure, Linux upute, networking dokumentaciju ili onboarding. U takvim slučajevima nije dovoljno da odgovor zvuči uvjerljivo. Mora biti vezan uz dokument koji organizacija stvarno koristi.
Najvažnije postavke nisu samo tehničke
Chunk size, top-k, similarity threshold i temperature jesu važne postavke. Ali one ne mogu popraviti dokument koji je loše strukturiran. Ako je jedan chunk mješavina deset tema, model će lako spojiti dijelove koji ne pripadaju istom odgovoru.
Zato dobar RAG projekt ima dva dijela: sustav koji odgovara i proces koji priprema znanje. RAGnar pokriva prvi dio. RAGnar Knowledge Processor pokriva drugi.
Zaključak
Kvalitetan RAG sustav ne počinje pitanjem “koji model da koristimo?”, nego pitanjem “kako izgleda naše znanje?”.
Ako su dokumenti čisti, kratki, tematski jasni i dobro označeni, čak i manji lokalni modeli mogu dati korisne odgovore. Ako su dokumenti kaotični, ni veći model neće stalno spašavati loš ulaz.
RAGnar i RAGnar Knowledge Processor zajedno pokazuju praktičan smjer: privatni AI sustav koji ne pokušava zamijeniti dokumentaciju, nego je pretvara u nešto što se može brzo pretražiti, citirati i koristiti u svakodnevnom radu.